Wyzwanie rabusiów jest tutaj .
Wyzwanie gliniarzy: Zaprojektuj język programowania, który wydaje się być bezużyteczny do programowania, ale dopuszcza obliczenia (lub przynajmniej zakończenie zadania) za pomocą jakiegoś nieoczywistego mechanizmu.
Powinieneś zaprojektować prosty język programowania, który odczytuje kod z pliku wejściowego, a następnie robi ... coś. Musisz przygotować program rozwiązania, który znajdzie 3. największą liczbę na wejściu, gdy zostanie uruchomiony w tłumaczu. Musisz maksymalnie utrudnić rabusiom znalezienie programu rozwiązania. Pamiętaj, że złodzieje mogą opublikować dowolne rozwiązanie, które spełnia zadanie, a nie tylko to, o którym myślałeś.
To konkurs popularności. Celem gliniarzy jest zdobycie jak największej liczby głosów i przetrwanie 8 dni po opublikowaniu tłumacza bez pękania. W tym celu powinny pomóc następujące praktyki:
- Dokładne wyjaśnienie semantyki języka
- Pisanie czytelnego kodu
Następujące taktyki są zdecydowanie odradzane:
- Korzystanie z szyfrowania, skrótów lub innych metod kryptograficznych. Jeśli widzisz język, który wykorzystuje szyfrowanie RSA lub odmawia wykonania programu, chyba że jego skrót SHA-3 jest równy 0x1936206392306, nie wahaj się zlekceważyć.
Wyzwanie rabusiów: Napisz program, który znajdzie trzecią co do wielkości liczbę całkowitą na wejściu, gdy zostanie uruchomiony w interpretatorze gliniarzy.
Ten jest stosunkowo prosty. Aby złamać odpowiedź gliniarza, musisz utworzyć program, który wykona zadanie po uruchomieniu w swoim tłumaczu. Kiedy złamiesz odpowiedź, opublikuj komentarz z napisem „Pęknięty” w odpowiedzi policjanta prowadzący do twojego postu. Ten, kto złamie najwięcej gliniarzy, wygrywa nić rabusiów.
Zasady we / wy
- Tłumacze powinni pobrać nazwę pliku w wierszu poleceń programu i używać standardowych danych wejściowych i wyjściowych podczas jego uruchamiania.
- Dane wejściowe będą podawane jako jednoargumentowe i będą składały się wyłącznie ze znaków
0oraz1(48 i 49 w ASCII). Liczba N jest kodowana jako N,1spo której następuje0. Istnieje dodatkowy0przed końcem pliku. Przykład: Dla sekwencji (3, 3, 1, 14) wejście to11101110101111111111111100. - Dane wejściowe mają co najmniej 3 cyfry. Wszystkie liczby są dodatnimi liczbami całkowitymi.
- Wyjście zostanie ocenione na podstawie liczby
1s wydrukowanych przed zatrzymaniem programu. Inne postacie są ignorowane.
W poniższych przykładach pierwszym wierszem jest dane wejściowe w formacie dziesiętnym; drugi to rzeczywisty program wejściowy; trzeci to przykładowy wynik.
1, 1, 3
101011100
1
15, 18, 7, 2, 15, 12, 3, 1, 7, 17, 2, 13, 6, 8, 17, 7, 15, 11, 17, 2
111111111111111011111111111111111101111111011011111111111111101111111111110111010111111101111111111111111101101111111111111011111101111111101111111111111111101111111011111111111111101111111111101111111111111111101100
111111,ir23j11111111111u
247, 367, 863, 773, 808, 614, 2
<omitted>
<contains 773 1's>
Nudne zasady dla odpowiedzi gliniarzy:
- Aby zapobiec bezpieczeństwu z powodu niejasności, tłumacz powinien być napisany w języku znajdującym się w pierwszej setce tego indeksu TIOBE i mieć swobodnie dostępny kompilator / tłumacz.
- Tłumacz nie może tłumaczyć języka, który został opublikowany przed tym wyzwaniem.
- Tłumacz powinien pasować do twojego postu i nie może być hostowany na zewnątrz.
- Tłumacz powinien być deterministyczny
- Tłumacz powinien być przenośny i zgodny ze standardem własnego języka; nie używaj niezdefiniowanego zachowania ani błędów
- Jeśli program rozwiązania jest zbyt długi, aby zmieścił się w odpowiedzi, musisz opublikować program, który go generuje.
- Program rozwiązania powinien składać się tylko z ASCII do druku i znaków nowej linii.
- Musisz wykonać program rozwiązania w mniej niż 1 godzinę na własnym komputerze dla każdego z powyższych przykładowych danych wejściowych.
- Program powinien działać na liczbach całkowitych mniejszych niż 10 6 i dowolnej liczbie całkowitej mniejszej niż 10 6 (niekoniecznie poniżej godziny), pod warunkiem, że całkowita długość wejściowa jest mniejsza niż 10 9 .
- Aby uzyskać bezpieczeństwo, policjant musi edytować program rozwiązania w odpowiedzi po upływie 8 dni.
Punktacja
Policjant, który staje się bezpieczny z najwyższym wynikiem i wynikiem dodatnim, wygrywa to pytanie.
Odpowiedzi:
Changeling (bezpieczny)
ShapeScript
ShapeScript to naturalnie występujący język programowania. Zmiennokształtni (lub Changelingowie , jak wolą nazywać się) mogą przekształcić się w zestaw instrukcji, które pozwalają im przetwarzać dane.
ShapeScript jest językiem stosowym o stosunkowo prostej składni. Nic dziwnego, że większość jego wbudowanych funkcji polega na zmianie kształtu łańcuchów. Jest interpretowany, znak po znaku, w następujący sposób:
'i"rozpocznij dosłowny ciąg znaków.Dopóki pasujący cytat nie zostanie znaleziony w kodzie źródłowym, wszystkie znaki między tymi pasującymi cytatami są gromadzone w ciągu, który jest następnie wypychany na stos.
0aby9przesunąć liczby całkowite od 0 do 9 na stosie. Zauważ, że10wypycha dwie liczby całkowite.!wyrzuca ciąg ze stosu i próbuje ocenić go jako ShapeScript.?wyskakuje liczba całkowita ze stosu i wypycha kopię elementu stosu pod tym indeksem.Indeks 0 odpowiada pierwszemu stosowi (LIFO), a indeks -1 najniższemu.
_wyskakuje iterowalny ze stosu i przesuwa jego długość.@wyrzuca dwa elementy ze stosu i przesuwa je w odwrotnej kolejności.$wyrzuca dwa łańcuchy ze stosu i dzieli najniższy z nich w przypadku wystąpienia najwyższego. Wynikowa lista jest przekazywana w zamian.&wyskakuje ciąg (najwyższy) i iterowalny ze stosu i dołącza iterowalny, używając łańcucha jako separatora. Powstały ciąg jest wypychany w zamian.Jeśli ShapeScript jest używany na naszej planecie, ponieważ pytony są podmieńcach najbliższych krewnych na ziemi, wszystkie inne znaki c pop dwa elementy x i y (najwyższa) ze stosu, i próba oceny kodu Pythona
x c y.Na przykład sekwencja znaków
23+będzie się oceniać2+3, podczas gdy sekwencja znaków"one"3*będzie się oceniać'one'*3, a sekwencja znaków1''Abędzie się oceniać1A''.W ostatnim przypadku, ponieważ wynik nie jest prawidłowym Pythonem, Changeling narzekałby, że jego obecny kształt nie jest celowany (błąd składniowy), ponieważ nie jest prawidłowym ShapeScript.
Przed wykonaniem kodu interpreter umieści dane wejściowe użytkownika w postaci łańcucha na stosie. Po wykonaniu kodu źródłowego interpreter wydrukuje wszystkie elementy na stosie. Jeśli jakakolwiek część pomiędzy nimi zawiedzie, Changeling narzeka, że jego obecny kształt jest nieodpowiedni (błąd w czasie wykonywania).
Zmiana kształtu
W swoim naturalnym stanie Changelingi nie przybierają kształtu ShapeScript. Jednak niektóre z nich mogą przekształcić się w jeden potencjalny kod źródłowy (co niekoniecznie jest przydatne lub nawet poprawne składniowo).
Wszyscy kwalifikujący się Changelingi mają następującą naturalną formę:
Wszystkie wiersze muszą mieć tę samą liczbę znaków.
Wszystkie wiersze muszą składać się z drukowalnych znaków ASCII, po których następuje pojedynczy wiersz.
Liczba wierszy musi odpowiadać liczbie znaków do wydrukowania w wierszu.
Na przykład sekwencja bajtów
ab\ncd\njest odpowiednią zmianą nazw.Próba przejścia na ShapeScript zmienia się w następującą transformację:
Początkowo nie ma kodu źródłowego.
Dla każdej linii dzieje się:
Akumulator Changelinga jest ustawiony na zero.
Dla każdego znaku c linii (łącznie z końcowym podawaniem linii) punkt kodowy c jest XORowany z akumulatorem podzielonym przez 2, a znak Unicode odpowiadający wynikowemu punktowi kodowemu jest dołączany do kodu źródłowego.
Następnie do akumulatora dodaje się różnicę między punktem kodowym c i punktem kodowym spacji (32).
Jeśli jakakolwiek część powyższego zawiodła, Changeling narzeka, że jej obecny kształt jest nieprzyjemny.
Po przetworzeniu wszystkich linii transformacja Changelinga w (prawdopodobnie poprawną) ShapeScript jest zakończona, a wynikowy kod jest wykonywany.
Rozwiązanie (ShapeScript)
ShapeScript faktycznie okazał się całkiem użyteczny; może nawet przeprowadzać testy pierwotności ( dowód ), a zatem spełnia naszą definicję języka programowania.
Ponownie opublikowałem ShapeScript na GitHub , z nieco zmodyfikowaną składnią i lepszymi I / O.
Kod wykonuje następujące czynności:
Rozwiązanie (zmiana)
Podobnie jak wszystkie programy Changeling, ten kod ma końcowy kanał.
ShapeScript natychmiast popełni błąd przy każdym znaku, którego nie rozumie, ale możemy popchnąć dowolne ciągi jako wypełniacze i pop je później. To pozwala nam umieścić tylko niewielką ilość kodu w każdej linii (na początku, gdzie akumulator jest mały), a następnie otwierać
". Jeśli zaczynamy od następnego wiersza"#, zamykamy i usuwamy ciąg bez wpływu na rzeczywisty kod.Ponadto musimy pokonać trzy niewielkie przeszkody:
Długi ciąg w kodzie ShapeScript jest pojedynczym tokenem i nie będziemy w stanie dopasować go do linii.
Będziemy naciskać ten ciąg w kawałki (
'@','1?'etc.), które będziemy łączyć później.Punkt kodowy
_jest raczej wysoki, a wypychanie'_'będzie problematyczne.Będziemy jednak mogli
'_@'bez wysiłku naciskać , a następnie'@'wykonać kolejne, aby cofnąć zamianę.Kod ShapeScript, który wygeneruje nasze Changeling, wygląda następująco 1 :
Znalazłem kod Changeling, uruchamiając powyższy kod ShapeScript przez ten konwerter . 2)
Tłumacz (Python 3)
1 Każda linia jest dopełniana losowym śmieciem do ilości linii, a kanały nie są tak naprawdę obecne.
2 Liczby u dołu wskazują najniższy i najwyższy punkt kodu w Kodzie zmiany, który musi zawierać się w przedziale od 32 do 126.
źródło
0"#002?'+'&'0'$'0?2?-@2?>*+00'&!++'1'*'0'+@1?$0?''&@_2-2?*@+@"3*!@#. Zrezygnowałem jednak ze znalezienia Changeling. Nawet przeplatane najczęściej bezużytecznymi instrukcjami, nie byłem w stanie uzyskać więcej niż 20 bajtów.Shuffle (napisane w C ++), pęknięty! autor: Martin
Edytuj Martin go złamał. Aby zobaczyć jego rozwiązanie, kliknij link. Moje rozwiązanie również zostało dodane.
Edytuj Naprawiono
print-dpolecenie, aby móc obsługiwać zarówno rejestry, jak i stosy. Ponieważ jest to polecenie debugowania, które nie jest dozwolone w rozwiązaniu, nie powinno to wpłynąć na nikogo używającego poprzedniej wersji interpreteraNadal jestem nowy, więc jeśli coś jest nie tak z moją odpowiedzią lub tłumaczem, daj mi znać. Poproś o wyjaśnienie, jeśli coś nie jest jasne.
Nie sądzę, że będzie to zbyt strasznie trudne, ale mam nadzieję, że będzie to pewne wyzwanie. To, co sprawia, że odtwarzanie losowe jest dość bezużyteczne, polega na tym, że będzie ono drukowane tylko wtedy, gdy rzeczy będą na swoim miejscu.
-> Podstawy:
Są 24 stosy, nazywamy je
stack1, ... stack24. Te stosy znajdują się na liście. Na początku dowolnego programu stosy te mają zerowe przesunięcie i zaczynają się na swoim właściwym miejscu, tj. Stos i na i-tej pozycji na liście (zauważ, że indeksujemy od 1, w przeciwieństwie do C ++). Podczas trwania programu kolejność stosów na liście będzie się zmieniać. Jest to ważne z powodów, które zostaną wyjaśnione podczas omawiania poleceń.Dostępnych jest 5 rejestrów. Są one nazwane
Alberto,Gertrude,Hans,Leopold,ShabbySam. Każdy z nich jest ustawiony na zero na początku programu.Tak więc na początku dowolnego programu istnieją 24 stosy, każdy ma swój numer zgodny z indeksem na liście stosów. Każdy stos ma dokładnie jedno zero na górze. Każdy z pięciu rejestrów jest inicjowany na zero.
-> Polecenia i składnia :
Dostępnych jest 13 poleceń (polecenie debugowania +1) w trybie losowym. Są one następujące
cinpushto polecenie nie przyjmuje argumentów. Oczekuje na dane wejściowe z wiersza poleceń w sposób opisany w pytaniu (inne dane wejściowe doprowadzą do nieokreślonych / niezdefiniowanych wyników). Następnie dzieli łańcuch wejściowy na liczby całkowite, np.101011100->1,1,3. Dla każdego otrzymanego wejścia wykonuje następujące czynności: (1) permutuje listę stosów na podstawie wartości. Niech dana liczba całkowita nazywa się a . Jeśli jest mniejsza niż 10 robi permutacja u . Jeśli a wynosi od 9 do 30 (nieuwzględniające), wykonuje permutację d . W przeciwnym razie robi permutację r . (2) Następnie przesuwa ana stosie, który jest pierwszy na liście. Zauważ, że nie mam na myślistack1(chociaż może być tak, żestack1jest pierwszy na liście). Permutacje są zdefiniowane poniżej. Ponieważcinpushjest to jedyny sposób na uzyskanie wkładu użytkownika , musi pojawić się w dowolnym rozwiązaniu.mov value registermovKomenda jest w zasadzie przypisania zmiennej. Przypisujevaluedoregister.valuemoże przybierać różne formy: może to być (1) liczba całkowita, np.47(2) nazwa innego rejestru, np.Hans(3) indeks stosu, po którym następuje „s”, np4s. Zauważ, że jest to indeks na liście, a nie numer stosu. Jako taka liczba nie powinna przekraczać 24.Niektóre
movprzykłady:movfs index registerTo oznacza „przenieś ze stosu”. Jest podobny domovpolecenia. Istnieje, abyś mógł uzyskać dostęp do stosu indeksowanego przez rejestr. Na przykład, jeśli wcześniej ustawisz Hansa na 4 (mov 4 Hans), możesz użyć,movfs Hans Gertrudeaby ustawić Gertrude na szczyt stosu 4. Tego rodzaju zachowanie nie jest dostępne po prostu za pomocąmov.inc registerzwiększa wartość rejestru o 1.dec registerzmniejsza wartość rejestru o 1.compg value value registerOznacza to „porównaj większe”. Ustawia rejestr równy większej z dwóch wartości.valuemoże być liczbą całkowitą, rejestrem lub indeksem stosu, po którym następuje „s”, jak wyżej.compl value value register„porównaj mniej” tak samo jak powyżej, z tym wyjątkiem, że przyjmuje mniejszą wartość.gte value1 value2 registerSprawdza, czyvalue1 >= value2następnie wstawia wartość logiczną (jako 1 lub 0) doregister.POP!! indexwyskakuje z góry stosu indeksowanegoindexna liście stosów.jmp labelprzeskakuje bezwarunkowo do etykietylabel. To dobry czas na rozmowę o wytwórniach. Etykieta to słowo, po którym następuje „:”. Tłumacz interpretuje etykiety, więc możesz przeskakiwać zarówno do etykiet, jak i do tyłu.jz value labelskacze dolabelifvaluewynosi zero.jnz value labelprzeskakuje dolabeljeślivaluejest niezerowe.Przykłady etykiet i skoków:
"shuffle" permutationOto polecenie losowania. Pozwala to na permutację listy stosów. Istnieją trzy ważne permutacje, które mogą być używane jako argumenty,l,f, ib.print registerTo sprawdza, czy wszystkie stosy znajdują się w swoich początkowych pozycjach, tj. Stos i znajduje się na indeksie i na liście stosów. W takim przypadku wypisuje wartośćregisterw unary. W przeciwnym razie drukuje paskudny błąd. Jak widać, aby wszystko wyprowadzić, stosy muszą znajdować się we właściwych miejscach.done!to mówi programowi, aby zakończył pracę bez błędu. Jeśli program zakończy się bezdone!, wypisze w konsoli numer na górze każdego stosu, a następnie numer stosu. Kolejność drukowania stosów to kolejność, w jakiej pojawiają się na liście stosów. Jeśli stos jest pusty, zostanie pominięty. To zachowanie służy do debugowania i nie może być użyte w rozwiązaniu.print-d valuewypisuje podaną wartość stosu, rejestru lub liczby całkowitej (aby uzyskać dostęp do stosu i , przekazaćisjako argument, jak wyjaśniono powyżej). Jest to narzędzie do debugowania i nie jest częścią języka, ponieważ nie jest dozwolone w rozwiązaniu.-> Oto kod tłumacza
Cała parsowanie odbywa się w głównej funkcji. To tutaj znajdziesz analizowanie określonych poleceń.
-> Permutacje Permutacje permutują elementy listy stosów w następujący sposób:
Gdzie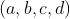 to znaczy
to znaczy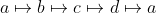
(Pojawiają się one również w kodzie tłumacza. Jeśli występuje rozbieżność, tłumacz jest poprawny).
-> Prosty przykład
Te dwa proste programy drukują liczby od 24 do 1 (jednoargumentowo) bez białych znaków.
lub
Są to ten sam program.
Objaśnienie i rozwiązanie:
Martin ma również dobre wyjaśnienie w swojej odpowiedzi .
Jak zorientował się Martin, język ten został zainspirowany kieszonkową kostką (czyli kostką Rubika 2x2). 24 stosy są jak 24 pojedyncze kwadraty na kostce. Permutacje są podstawowymi dozwolonymi ruchami: góra, dół, prawo, lewo, przód, tył.
Główna walka polega na tym, że kiedy wartości są wypychane, używane są tylko trzy ruchy: góra, dół i prawo. Nie masz jednak dostępu do tych ruchów podczas „tasowania” stosów. Masz tylko trzy pozostałe ruchy.
Jak się okazuje, oba zestawy trzech ruchów faktycznie obejmują całą grupę (tj. Są generatorami), więc problem można rozwiązać. Oznacza to, że możesz faktycznie rozwiązać dowolną kostkę Rubika 2x2, używając tylko 3 ruchów.
Pozostaje tylko dowiedzieć się, jak cofnąć ruchy w górę, w dół i w prawo za pomocą pozostałych trzech. W tym celu zastosowałem system algebry komputerowej o nazwie GAP .
Po cofnięciu permutacji znalezienie trzeciej największej liczby jest dość trywialne.
źródło
Brian & Chuck , Cracked by cardboard_box
Od jakiegoś czasu byłem zaintrygowany ideą języka programowania, w którym dwa programy współdziałają ze sobą (prawdopodobnie zainspirowane przez ROCB ). To wyzwanie stanowiło miłą zachętę do rozwiązania tej koncepcji, jednocześnie starając się, aby język był jak najmniejszy. Celem projektu było uzupełnienie języka Turinga, a każda jego część oddzielnie nie jest kompletna. Co więcej, nawet oba z nich razem nie powinny być pełne Turinga bez korzystania z manipulacji kodem źródłowym. Myślę, że mi się to udało, ale formalnie nie udowodniłem żadnej z tych rzeczy. Więc bez zbędnych ceregieli przedstawiam wam ...
Bohaterowie
Brian i Chuck to dwa programy podobne do Brainfuck. Tylko jeden z nich jest wykonywany w danym momencie, zaczynając od Briana. Problem polega na tym, że taśma pamięci Briana jest również kodem źródłowym Chucka. Taśma pamięci Chucka jest także kodem źródłowym Briana. Co więcej, taśma Briana jest również wskaźnikiem instrukcji Chucka i vice versa. Taśmy są częściowo nieskończone (tj. Nieskończone po prawej stronie) i mogą zawierać podpisane liczby całkowite o dowolnej dokładności, zainicjowane na zero (chyba że kod źródłowy stanowi inaczej).
Ponieważ kod źródłowy jest również taśmą pamięci, polecenia są technicznie definiowane przez wartości całkowite, ale odpowiadają rozsądnym znakom. Istnieją następujące polecenia:
,(44): Przeczytaj bajt ze STDIN do bieżącej komórki pamięci. Tylko Brian może to zrobić. To polecenie nie działa dla Chucka..(46): Zapisz bieżącą komórkę pamięci, modulo 256, jako bajt do STDOUT. Tylko Chuck może to zrobić. To polecenie nie działa dla Briana.+(43): Zwiększ bieżącą komórkę pamięci.-(45): Zmniejsz bieżącą komórkę pamięci.?(63): Jeśli bieżąca komórka pamięci ma wartość zero, oznacza to brak operacji. W przeciwnym razie przejmij kontrolę nad innym programem. Głowica taśmy w używanym programie?pozostanie w?. Głowica taśmy drugiego programu przesunie jedną komórkę w prawo przed wykonaniem pierwszego polecenia (więc komórka używana jako test nie jest wykonywana sama).<(60): Przesuń głowicę taśmy o jedną komórkę w lewo. Jest to niemożliwe, jeśli głowica taśmy znajduje się już na lewym końcu taśmy.>(62): Przesuń głowicę taśmy o jedną komórkę w prawo.{(123): Kilkakrotnie przesuń głowicę taśmy w lewo, aż bieżąca komórka wyniesie zero lub dojdzie do lewego końca taśmy.}(125): Kilkakrotnie przesuń głowicę taśmy w prawo, aż bieżąca komórka wyniesie zero.Program kończy się, gdy wskaźnik instrukcji aktywnego programu osiągnie punkt, w którym nie ma już instrukcji po jego prawej stronie.
Kod źródłowy
Plik źródłowy jest przetwarzany w następujący sposób:
```, plik zostanie podzielony na dwie części wokół pierwszego wystąpienia tego ciągu. Wszystkie wiodące i końcowe białe znaki są usuwane, a pierwsza część jest używana jako kod źródłowy dla Briana, a druga dla Chucka._w obu programach są zastępowane bajtami NULL.Na przykład następujący plik źródłowy
Dałoby to następujące początkowe taśmy:
Tłumacz
Tłumacz jest napisany w języku Ruby. Pobiera dwie flagi wiersza polecenia, których nie może używać żadne rozwiązanie (ponieważ nie są one częścią rzeczywistej specyfikacji języka):
-d: Z tą flagą Brian i Chuck rozumieją jeszcze dwa polecenia.!wypisze ciąg znaków obu taśm pamięci, aktywny program jest wymieniony jako pierwszy (a^zaznaczy bieżące głowice taśm).@zrobi to również, ale następnie natychmiast zakończy program. Ponieważ jestem leniwy, żadna z nich nie działa, jeśli są ostatnim poleceniem w programie, więc jeśli chcesz ich tam użyć, powtórz je lub napisz po nich brak op.-D: To jest pełny tryb debugowania. Wyświetli te same informacje debugowania, co!po każdym pojedynczym tiku.@działa również w tym trybie.Oto kod:
Oto moje (odręcznie) rozwiązanie problemu:
Ten kod można uruchomić w obecnej postaci, ponieważ wszystkie adnotacje używają opcji no-ops i są pomijane przez
{i}.Podstawową ideą jest:
1s zwiększaj ten element.Kiedy czytamy a
0, zrób porządek. Jeśli wynikowa liczba całkowita była większa od zera, wróć do 1.Teraz mamy listę liczb wejściowych na końcu taśmy Chucka i znamy długość listy.
Odejmij 2 od długości listy (więc poniższe kroki ignorują dwa największe elementy), wywołaj to
N.Natomiast
N > 0zwiększ sumę bieżącą, a następnie zmniejsz wszystkie elementy listy. Ilekroć element listy osiąga zero, zmniejsza sięN.Pod koniec tego bieżąca suma będzie zawierać trzecią co do wielkości liczbę w wejściu,
M.Napisz
Mkopie.do końca taśmy Chucka.1na taśmie Briana, a następnie uruchom te wygenerowane.na końcu.Po zakończeniu zdałem sobie sprawę, że w niektórych miejscach mogę to bardzo uprościć. Na przykład zamiast śledzić licznik i zapisywać je
.na taśmie Chucka, mógłbym po prostu wydrukować1od razu, za każdym razem, zanim zmniejszę wszystkie elementy listy. Jednak wprowadzanie zmian w tym kodzie jest dość uciążliwe, ponieważ propaguje inne zmiany w całym miejscu, więc nie zawracałem sobie głowy wprowadzaniem zmian.Interesujące jest to, jak śledzić listę i jak iterować po niej. Nie możesz po prostu przechowywać liczb na taśmie Chucka, ponieważ wtedy, jeśli chcesz sprawdzić warunek na jednym z elementów listy, ryzykujesz wykonanie pozostałej części listy, która może zawierać prawidłowy kod. Nie wiesz również, jak długa będzie ta lista, więc nie możesz po prostu zarezerwować miejsca przed kodem Chucka.
Kolejny problem polega na tym, że musimy pozostawić listę do zmniejszenia
Npodczas przetwarzania i musimy wrócić do tego samego miejsca, w którym byliśmy wcześniej. Ale{i}po prostu pominie całą listę.Musimy więc dynamicznie napisać kod na Chucku. W rzeczywistości każdy element listy
ima postać:1jest znacznikiem, który możemy ustawić na zero, aby wskazać, gdzie zakończyliśmy przetwarzanie listy. Jego celem jest złapanie{lub}który po prostu przekaże kod ii. Używamy również tej wartości, aby sprawdzić, czy jesteśmy na końcu listy podczas przetwarzania, więc dopóki tego nie zrobimy, będzie to możliwe,1a warunek?przełączy kontrolę na Chucka.Code Asłuży do obsługi tej sytuacji i odpowiedniego przeniesienia własności intelektualnej na Briana.Teraz, kiedy zmniejszamy
i, musimy sprawdzić, czyijest już zero. Chociaż tak nie jest,?ponownie przełączy kontrolę, więcCode Bjest to, aby sobie z tym poradzić.źródło
HPR, napisane w Pythonie 3 ( Cracked przez TheNumberOne )
HPR (nazwa nic nie znaczy) to język do przetwarzania list liczb całkowitych. Został zaprojektowany jako minimalistyczny , wyjątkowo ograniczony i wolny od „sztucznych” ograniczeń . Programowanie w HPR jest bolesne, nie dlatego, że musisz rozwiązać zagadkę, aby tłumacz nie krzyczał na ciebie, ale dlatego, że trudno jest zmusić program do zrobienia czegoś pożytecznego. Nie wiem, czy HPR jest w stanie zrobić coś znacznie bardziej interesującego niż obliczenie trzeciego co do wielkości elementu listy.
Specyfikacja języka
Program HPR jest uruchamiany w środowisku , które jest nieuporządkowanym wolnym od duplikatów zbiorem nieujemnych liczb całkowitych i list nieujemnych liczb całkowitych. Początkowo środowisko zawiera tylko listę danych wejściowych (interpreter analizuje je dla Ciebie). Istnieją trzy polecenia i dwa operatory „sterowania przepływem”, które modyfikują środowisko:
*usuwa pierwszy element z każdej niepustej listy w środowisku i umieszcza go w środowisku. Nie ma to wpływu na puste listy. Na przykład przekształca się-zmniejsza wszystkie liczby w środowisku, a następnie usuwa elementy ujemne. Na przykład przekształca się$obraca każdą listę w środowisku o krok w lewo. Na przykład przekształca się!(A)(B), gdzieAiBsą programami, jest w zasadziewhilepętlą. Wykonuje „akcję”,Adopóki „test”Bnie spowoduje pustego środowiska. Może to spowodować nieskończoną pętlę.#(A)(B), gdzieAiBsą programami, stosuje sięAiBdo bieżącego środowiska i przyjmuje symetryczną różnicę wyników.Polecenia są wykonywane od lewej do prawej. Na koniec rozmiar środowiska jest drukowany w jednym.
Tłumacz
Ten interpreter zawiera polecenie debugowania
?, które drukuje środowisko bez modyfikowania go. Nie powinno pojawić się w żadnym rozwiązaniu zadania. Wszelkie znaki oprócz*-$!#()?są po prostu ignorowane, dzięki czemu można pisać komentarze bezpośrednio w kodzie. Na koniec interpreter rozpoznaje ten idiom!(A)(#(A)())jako „działaj,Aaż wynik się nie zmieni” i optymalizuje go pod kątem dodatkowej prędkości (potrzebowałem go, aby moje rozwiązanie zakończyło się w niecałą godzinę w ostatnim przypadku testowym).Moje rozwiązanie
Moje referencyjne rozwiązanie ma 484 bajty długości, jest więc dość krótkie w porównaniu do 3271-bajtowego programu TheNumberOne. Jest to najprawdopodobniej ze względu na wyrafinowany i niesamowity system makr TheNumberOne opracowany do programowania w HPR. Główna idea obu naszych programów jest podobna:
Jednak, o ile wiem, dokładne szczegóły implementacji są zupełnie inne. Oto moje rozwiązanie:
A oto skomentowany program Pythona, który go produkuje (nic szczególnego, tylko podstawowa manipulacja ciągiem, aby pozbyć się całego powtórzenia):
źródło
TKDYNS (To Kill the Dragon, You Need a Sword) - Pęknięty przez Martina Büttnera
EDYCJA: Dodałem moje rozwiązanie i wyjaśnienie poniżej głównego postu.
tło
W tym języku przejmujesz kontrolę nad dzielnym wojownikiem, którego zadaniem jest zabicie straszliwego smoka. Smok żyje w podziemnym labiryncie, pełnym niebezpieczeństw i niebezpieczeństw, i do tej pory nikt nie był w stanie go zmapować i przeżyć. Oznacza to, że musisz nawigować do smoka w ciemnościach, mając do dyspozycji jedynie intuicję i odwagę.
...
Cóż, niezupełnie. Przywiozłeś ze sobą prawie nieograniczoną liczbę stworów jednorazowego użytku, a oni są gotowi iść przed tobą, aby odkryć bezpieczną trasę. Niestety wszystkie są grube jak dwie krótkie deski i zrobią tylko to, co im każesz. Od ciebie zależy wymyślenie sprytnej metody upewnienia się, że twoi stwory odkryją właściwą ścieżkę.
Więcej szczegółów
Legowisko smoka ma postać siatki 10x10. Pomiędzy niektórymi sąsiadującymi punktami na siatce znajduje się wąski chodnik; między innymi jest głęboka przepaść i pewna śmierć. Przykładowy układ siatki 4x4 może wyglądać następująco:
Wiesz, że zawsze jest sposób na przejście z jednego punktu do innego, ale nie więcej niż to zostało ci objawione.
Aby skutecznie pokonać smoka, musisz najpierw zebrać kilka przedmiotów, które będziesz mógł połączyć, aby stworzyć magiczne ostrze zabijające smoki. Dogodnie wszystkie elementy tej broni zostały rozrzucone wokół legowiska smoka. Musisz je tylko zebrać.
Skręt polega na tym, że każdy element broni został uwięziony w minie. Po każdym zebraniu zmienia się układ chodników. Wcześniej bezpieczne ścieżki mogły teraz prowadzić do pewnej śmierci i na odwrót.
Polecenia
Jest tylko 5 poprawnych poleceń.
<- Zrób krok w lewo>- Zrób krok w prawo^- Zrób krok w góręv- Zrób krok w dółc- Zbierz wszystkie przedmioty, które leżą na twojej obecnej pozycji. Jeśli były obecne przedmioty, układ legowiska zmienia się. Z pozycjami ponumerowanymi w rzędach jak powyżej, weź modulo pozycji 10. W interpretera jest 10 układów zakodowanych na stałe, a układ zmienia się na odpowiedni. Na przykład, jeśli jesteś na pozycji 13, układ zmienia się nalayouts[3]Układy pojawiające się w interpetrze zostały zakodowane na liczbach całkowitych w następujący sposób:
Pusty układ jest kodowany na zero.
Dla każdej krawędzi w układzie niech
xbędzie mniejsza z dwóch łączonych pozycji.Jeśli krok jest poziomy, dodaj
2^(2*x)do kodowania (to moc, nie XOR)Jeśli krok jest pionowy, dodaj
2^(2*x + 1)do kodowania.Przepływ wykonania
Interpreter jest uruchamiany z nazwą pliku źródłowego jako argumentem wiersza poleceń.
Po uruchomieniu tłumacza poprosi użytkownika o wykonanie zadania. Dane wejściowe powinny mieć postać opisaną w pytaniu i określać miejsca w legowisku elementów broni. Konkretnie, każda liczba całkowita wejściowa jest pobierana modulo 100 i umieszczana w odpowiednim miejscu w legowisku.
Każdy program źródłowy składa się z kilku wierszy, a każdy wiersz składa się z sekwencji powyżej 5 prawidłowych znaków. Te linie przedstawiają twoich stworów. Ty, wojowniku, śledź sekwencję działań, o których wiadomo, że są bezpieczne. Początkowo nic nie wiesz o legowisku, więc ta sekwencja jest pusta. Biorąc kolejno każdego stwora, wykonuje się następujące czynności, zaczynając od pozycji 0:
Sługus jest instruowany, aby wykonywał wszystkie działania, o których wiadomo, że są bezpieczne, a następnie działania we własnym wierszu kodu.
Jeśli stwór zginie w dowolnym momencie, zostaniesz o tym powiadomiony, a legowisko powróci do pierwotnej konfiguracji. Wszystkie przedmioty są wymieniane, a chodniki wracają do swoich pozycji początkowych.
Jeśli natomiast stwór przeżyje, to i tak go odparujesz - w końcu to tylko stwór. Tak jak poprzednio, powoduje to zresetowanie legowiska do jego początkowego stanu, ale tym razem dołączasz akcje z linii kodu stwora do sekwencji akcji, o których wiadomo, że są bezpieczne.
Gdy wszystkie stwory zostaną wyczerpane, ty, wojownik, wykonaj wszystkie czynności, o których wiadomo, że są bezpieczne, ponownie zaczynając od pozycji 0. Istnieją dwa możliwe wyniki:
Zbierasz wszystkie elementy broni - w tym przypadku z powodzeniem zabijasz smoka i pojawia się ekscytująca wiadomość o zwycięstwie. Ta wiadomość o zwycięstwie będzie zawierać, między innymi,
nte, w którychnjest trzecią najwyższą liczbą podaną jako dane wejściowe.Nie udało ci się zebrać niektórych elementów broni - w tym przypadku smok żyje dalej i nie udało ci się.
Kod tłumacza (Python 2)
Powodzenia, dzielny wojowniku.
Moje rozwiązanie i wyjaśnienie
Oto skrypt w języku Python, który generuje kod źródłowy w celu rozwiązania problemu. Co ciekawe, końcowy kod źródłowy Martina jest około 5 razy mniejszy niż kod wygenerowany przez mój skrypt. Z drugiej strony mój skrypt do generowania kodu jest około 15 razy mniejszy niż program Mathematica Martina ...
Podstawowa struktura
Generuje to 990 wierszy kodu źródłowego, które występują w grupach po 10. Pierwsze 10 wierszy zawiera instrukcje, które próbują przenieść stwora z pozycji
0na pozycję1, a następnie zebrać przedmiot - jeden zestaw dla każdego możliwego układu. Wszystkie następne 10 wierszy zawiera instrukcje, które próbują przenieść stwora z pozycji1na pozycję2, a następnie zebrać przedmiot. I tak dalej ... Ścieżki te są obliczane za pomocąpathfunkcji w skrypcie - wykonuje proste wyszukiwanie w pierwszej kolejności.Jeśli możemy zapewnić, że w każdej grupie 10 dokładnie jeden stwór odniesie sukces, wówczas rozwiążemy problem.
Problem z podejściem
Nie zawsze może się zdarzyć, że dokładnie jeden stwór z grupy 10 odniesie sukces - na przykład stwór zaprojektowany do przejścia z pozycji
0do pozycji1może przypadkowo przejść z pozycji1do pozycji2(ze względu na podobieństwa w układach) i że błędne obliczenia będą się rozprzestrzeniać, potencjalnie powodując awarię.Jak to naprawić
Zastosowana przeze mnie poprawka była następująca:
Dla każdego stwora, który próbuje dostać się z pozycji
ndon+1, najpierw skieruj go z pozycjindo pozycji0(lewy górny róg) iz powrotem, a następnie z pozycjindo pozycji99(prawy dolny róg) iz powrotem. Te instrukcje można bezpiecznie wykonać tylko z pozycjin- każda inna pozycja początkowa, a stworek zejdzie z krawędzi.Te dodatkowe instrukcje zapobiegają zatem przypadkowemu stworowi udaniu się w miejsce, do którego nie są przeznaczone, a to gwarantuje, że dokładnie jeden stwór z każdej grupy 10 osób odniesie sukces. Zauważ, że niekoniecznie jest to stwór, którego się spodziewasz - może być tak, że stwór, który wierzy, że jest w układzie 0, odnosi sukces, nawet gdy tak naprawdę jesteśmy w układzie 7 - ale w każdym razie fakt, że mamy teraz zmieniona pozycja oznacza, że wszystkie inne stwory w grupie koniecznie zginą. Te dodatkowe kroki są obliczane przez
assert_atfunkcję, asafe_pathfunkcja zwraca ścieżkę, która jest konkatenacją tych dodatkowych kroków ze zwykłą ścieżką.źródło
Firetype, Cracked by Martin Büttner
Naprawdę dziwna mieszanka BF i CJam. A kto wie co jeszcze! Z pewnością będzie to łatwe, ale i tak było fajnie. FYI, nazwa nawiązuje do Vermillion Fire z Final Fantasy Type-0 .
UWAGA : Proszę wybaczyć mi wszelkie niejasności w tym opisie. Nie jestem najlepszym pisarzem ...: O
Martin złamał to bardzo szybko! To był mój oryginalny program do rozwiązania problemu:
Składnia
Skrypt Firetype to w zasadzie lista linii. Pierwszym znakiem każdej linii jest polecenie do uruchomienia. Puste linie to w zasadzie NOP.
Semantyka
Masz tablicę liczb całkowitych i wskaźnik (pomyśl BF). Możesz przesuwać elementy w lewo i prawo lub „pchać” na tablicę.
Popychanie
Kiedy „pchasz” element i jesteś na końcu tablicy, dodatkowy element zostanie dołączony na końcu. Jeśli nie będziesz na końcu, następny element zostanie zastąpiony. Niezależnie od tego wskaźnik będzie zawsze zwiększany.
Polecenia
_Naciśnij zero na tablicę.
+Zwiększ element przy bieżącym wskaźniku.
-Zmniejsz element pod bieżącym wskaźnikiem.
*Podwój element przy bieżącym wskaźniku.
/Przekrój element o połowę przy bieżącym wskaźniku.
%Weź element pod bieżącym wskaźnikiem i przeskocz o tyle linii i przesuń wskaźnik w lewo. Jeśli wartość jest ujemna, zamiast tego przeskocz do tyłu.
=Weź element pod bieżącym wskaźnikiem i przeskocz do tej linii + 1. Na przykład, jeśli bieżącym elementem jest
0, przejdzie do linii1. To również przesuwa wskaźnik w lewo.,Odczytaj znak ze standardowego wejścia i wciśnij jego wartość ASCII.
^Weź element pod bieżącym wskaźnikiem, zinterpretuj go jako wartość ASCII dla znaku i przekonwertuj go na liczbę całkowitą. Na przykład, jeśli bieżącą wartością jest
49(wartość ASCII z1), element przy bieżącym wskaźniku zostanie ustawiony na liczbę całkowitą1..Zapisz aktualny numer na ekranie.
!Weź element pod bieżącym wskaźnikiem i powtórz następną linię tyle razy. Przesuwa także wskaźnik w lewo.
<Przesuń wskaźnik w lewo. Jeśli jesteś już na początku, generowany jest błąd.
>Przesuń wskaźnik w prawo. Jeśli jesteś już na końcu, generowany jest błąd.
~Jeśli bieżący element jest niezerowy, zamień go na
0; w przeciwnym razie zastąp go1.|Kwadrat bieżącego elementu.
@Ustaw bieżący element na długość tablicy.
`Zduplikuj bieżący element.
\Sortuj elementy na wskaźniku i przed nim.
#Neguj bieżący element.
Tłumacz
Dostępne również w Github .
źródło
self.ptr-1dostępu, prawdopodobnieself.ptr>0nie powinieneś sprawdzać>=0. (Nie powinno to unieważniać żadnych prawidłowych programów, ale może spowodować, że niektóre programy będą działać przypadkowo, co nie powinno.)=ustawia wartośćarray() - 1, dokumentacja mówi+1?Acc !! (bezpieczny)
To jest baack ...
... i
mam nadzieję, żezdecydowanie bardziej odporne na luki.Przeczytałem już Acc! spec. Jak jest Acc !! różne?
W Acc !! , zmienne pętli wychodzą poza zakres, gdy pętla wychodzi. Możesz używać ich tylko wewnątrz pętli. Na zewnątrz pojawi się błąd „nazwa nie jest zdefiniowana”. Poza tą zmianą języki są identyczne.
Sprawozdania
Polecenia są analizowane linia po linii. Istnieją trzy rodzaje poleceń:
Count <var> while <cond>Zlicza
<var>od 0, o ile<cond>jest niezerowa, co odpowiada C ++for(int <var>=0; <cond>; <var>++). Licznikiem pętli może być dowolna pojedyncza mała litera. Warunkiem może być dowolne wyrażenie, niekoniecznie obejmujące zmienną pętli. Pętla zatrzymuje się, gdy wartość warunku staje się 0.Pętle wymagają nawiasów klamrowych w stylu K&R (w szczególności wariant Stroustrup ):
Jak wspomniano powyżej, zmienne pętli są dostępne tylko wewnątrz ich pętli ; próba odwołania się do nich później powoduje błąd.
Write <charcode>Wysyła pojedynczy znak o podanej wartości ASCII / Unicode na standardowe wyjście. Kod znaków może być dowolnym wyrażeniem.
Każde wyrażenie stojące samo w sobie jest oceniane i przypisywane z powrotem do akumulatora (który jest dostępny jako
_). Zatem np.3Jest stwierdzeniem, które ustawia akumulator na 3;_ + 1zwiększa akumulator; i_ * Nodczytuje znak i mnoży akumulator przez jego kod znaków.Uwaga: akumulator jest jedyną zmienną, do której można bezpośrednio przypisać; zmienne pętlowe i
Nmogą być używane w obliczeniach, ale nie mogą być modyfikowane.Akumulator ma początkowo wartość 0.
Wyrażenia
Wyrażenie może zawierać literały całkowite, zmienne pętli (
a-z)_dla akumulatora oraz specjalną wartośćN, która odczytuje znak i analizuje jego kod znaków za każdym razem, gdy jest używany. Uwaga: oznacza to, że masz tylko jeden strzał, aby przeczytać każdą postać; przy następnym użyciuNbędziesz czytać następny.Operatorzy to:
+, dodatek-, odejmowanie; jednoznaczna negacja*, mnożenie/, dzielenie liczb całkowitych%, modulo^, potęgowanieNawiasów można użyć w celu wymuszenia pierwszeństwa operacji. Każdy inny znak w wyrażeniu jest błędem składni.
Białe znaki i komentarze
Wiodące i końcowe białe znaki i puste linie są ignorowane. Biała spacja w nagłówkach pętli musi być dokładnie taka, jak pokazano, z pojedynczą spacją między nagłówkiem pętli i otwierającym nawias klamrowy. Białe spacje w wyrażeniach są opcjonalne.
#rozpoczyna komentarz jednowierszowy.Wejście wyjście
Acc !! oczekuje jednego wiersza znaków jako danych wejściowych. Każdy znak wejściowy można pobrać kolejno, a jego kod znaków przetworzyć za pomocą
N. Próba odczytania ostatniego znaku linii powoduje błąd. Znak może zostać wyprowadzony poprzez przekazanie jego kodu znaków doWriteinstrukcji.Interpretator
Tłumacz (napisany w Pythonie 3) tłumaczy Acc !! kod do Pythona i tak
execjest.Rozwiązanie
Upadek oryginalnego Acc! były zmiennymi pętlowymi, które nadal były dostępne poza ich pętlami. Pozwoliło to na zapisanie kopii akumulatora, co znacznie ułatwiło rozwiązanie.
Tutaj, bez dziury w pętli (przepraszam), mamy tylko akumulator do przechowywania rzeczy. Aby rozwiązać to zadanie, musimy przechowywać cztery dowolnie duże wartości. 1 Rozwiązanie: przeplataj ich bity i przechowuj wynikowy numer kombinacji w akumulatorze. Na przykład wartość akumulatora 6437 przechowałaby następujące dane (używając bitu najniższego rzędu jako flagi jednobitowej):
Możemy uzyskać dostęp do dowolnego fragmentu dowolnej liczby, dzieląc akumulator przez odpowiednią moc 2, mod 2. Pozwala to również na ustawienie lub przerzucanie poszczególnych bitów.
Na poziomie makro algorytm zapętla się nad liczbami jednoargumentowymi na wejściu. Odczytuje wartość na liczbę 0, a następnie wykonuje algorytm sortowania bąbelkowego, aby ustawić ją we właściwej pozycji w porównaniu z pozostałymi trzema liczbami. Wreszcie, odrzuca wartość, która pozostała w liczbie 0, ponieważ jest ona teraz najmniejszą z czterech i nigdy nie może być trzecią największą. Po zakończeniu pętli numer 1 jest trzecim co do wielkości, więc odrzucamy pozostałe i wysyłamy je.
Najtrudniejsza część (i powód, dla którego miałem globalne zmienne pętlowe w pierwszym wcieleniu) to porównanie dwóch liczb, aby wiedzieć, czy je zamienić. Aby porównać dwa bity, możemy zamienić tabelę prawdy w wyrażenie matematyczne; mój przełom dla Acc !! znajdował algorytm porównawczy, który przechodził od bitów niskiego rzędu do bitów wysokiego rzędu, ponieważ bez zmiennych globalnych nie ma możliwości zapętlenia bitów liczby od lewej do prawej. Bit najniższego rzędu akumulatora przechowuje flagę, która sygnalizuje, czy zamienić dwie rozważane liczby.
Podejrzewam, że Acc !! jest ukończony w Turinga, ale nie jestem pewien, czy chcę zadać sobie trud, aby to udowodnić.
Oto moje rozwiązanie z komentarzami:
1 Zgodnie ze specyfikacją pytania należy wspierać tylko wartości do 1 miliona. Cieszę się, że nikt nie skorzystał z tego dla łatwiejszego rozwiązania - choć nie jestem całkowicie pewien, jak byś zrobił porównania.
źródło
Picofuck (bezpieczny)
Picofuck jest podobny do Smallfuck . Działa na taśmie binarnej, która jest niezwiązana po prawej stronie, związana po lewej stronie. Ma następujące polecenia:
>przesuń wskaźnik w prawo<przesuń wskaźnik w lewo. Jeśli wskaźnik spadnie z taśmy, program się kończy.*odwróć bit przy wskaźniku(jeśli bit na wskaźniku to0, przejdź do następnego))nic nie rób - nawiasy w Picofuck toifbloki, a niewhilepętle..napisz, aby ustawić bit na wskaźniku jako ascii0lub1.,czytaj ze standardowego wejścia, aż napotkamy a0lub1, i przechowuj to w bicie przy wskaźniku.Kod Picofuck jest zawijany - po osiągnięciu końca programu jest kontynuowany od początku.
Ponadto Picofuck nie zezwala na zagnieżdżone nawiasy. Nawiasy pojawiające się w programie Picofuck muszą występować na przemian między
(i), zaczynając od(i kończąc na).Interpretator
Napisane w Pythonie 2.7
stosowanie:
python picofuck.py <source_file>Rozwiązanie
Poniższy program Python 2.7 wyświetla moje rozwiązanie, które można znaleźć tutaj
Mogę później edytować ten post z dokładniejszym wyjaśnieniem, jak to działa, ale okazuje się, że Picofuck jest w pełni Turinga.
źródło
PQRS - Bezpiecznie! / Dostarczone rozwiązanie
Podstawy
Wszystkie instrukcje dorozumiane mają cztery argumenty adresu pamięci:
Gdzie
vjest rozmiar pamięci w kwartetach.Pᵢ,Qᵢ,Rᵢ,SᵢSą podpisane liczb całkowitych w urządzeniu ojczystym wielkości (np 16, 32 lub 64 bity), które będziemy nazywać słowami.Dla każdego kwartetu
iimplikowana operacja,[]oznaczająca pośrednią, to:Zauważ, że Subleq jest podzbiorem PQRS .
Subleq okazał się kompletny, więc PQRS również powinien być kompletny!
Struktura programu
PQRS definiuje początkowy nagłówek w następujący sposób:
H₀ H₁ H₂ H₃jest zawsze pierwszą instrukcjąP₀ Q₀ R₀ S₀.H₀doH₃muszą być określone w czasie ładowania.PQRS ma podstawowe wejścia / wyjścia, ale wystarczające do wyzwania.
H₄ H₅: na początku programu wczytuje maksymalnieH₅standardowe znaki ASCII ze standardowego wejścia i zapisuje jako słowaH₄począwszy od indeksu .H₄iH₅muszą być zdefiniowane w czasie ładowania. Po przeczytaniuH₅zostanie ustawiona liczba odczytanych znaków (i zapisanych słów).H₆ H₇: po zakończeniu programu, zaczynając od indeksuH₆, wypisuje wszystkie bajty zawierająceH₇słowa na standardowe wyjście jako znaki ASCII.H₆iH₇należy je zdefiniować przed zakończeniem programu. Null bajty'\0'na wyjściu zostaną pominięte.Zakończenie
Zakończenie jest osiągane poprzez określenie
Sᵢgranici < 0lubi ≥ v.Wydziwianie
Kwartety
Pᵢ Qᵢ Rᵢ Sᵢnie muszą być wyrównane ani sekwencyjne, rozgałęzienia są dozwolone w odstępach między kwartetami.PQRS ma pośredni charakter, więc w przeciwieństwie do Subleq, istnieje wystarczająca elastyczność do implementacji podprogramów.
Kod może się sam modyfikować!
Interpretator
Tłumacz jest napisany w C:
Aby użyć, zapisz powyższe jako pqrs.c, a następnie skompiluj:
Przykładowy program
Echa wprowadzają do 40 znaków, poprzedzone „PQRS-”.
Aby uruchomić, zapisz powyższe jako
echo.pqrs, a następnie:Uruchamianie przypadków testowych:
Wszystkie przypadki testowe działają bardzo szybko, np. <500 ms.
Wyzwanie
PQRS można uznać za stabilny, więc wyzwanie rozpoczyna się 31.10.2015 13:00, a kończy 08.11.2015 13:00, razy w UTC.
Powodzenia!
Rozwiązanie
Język jest podobny do tego, który zastosowano w „Baby” - pierwszej na świecie elektronicznej maszynie cyfrowej z programami zapisanymi w pamięci. Na tej stronie znajduje się program do znalezienia najwyższego współczynnika liczby całkowitej w mniej niż 32 słowach (CRT!) Pamięci!
Odkryłem, że napisanie rozwiązania zgodnego ze specyfikacjami nie było zgodne z systemem operacyjnym i komputerem, którego używałem (pochodna Linux Ubuntu na nieco starszym sprzęcie). Po prostu żądał więcej pamięci niż dostępna i zrzucał rdzeń. W systemach operacyjnych z zaawansowanym zarządzaniem pamięcią wirtualną lub na maszynach z pamięcią co najmniej 8 GB można prawdopodobnie uruchomić rozwiązanie zgodnie ze specyfikacją. Podałem oba rozwiązania.
Bardzo trudno jest pisać bezpośrednio w PQRS , podobnie jak pisanie w języku maszynowym, może nawet mikrokod. Zamiast tego łatwiej jest pisać w jakimś języku asemblerowym, niż go „kompilować”. Poniżej znajduje się opisany język asemblera dla rozwiązania zoptymalizowanego do uruchamiania przypadków testowych:
To, co robi, to analizuje dane wejściowe, konwertując jednowymiarowy na dwójkowy, a następnie sortowanie bąbelkowe na liczbach z wartościami malejącymi, a następnie generuje trzecią co do wielkości wartość, przekształcając dwójkową z powrotem na jednostkową.
Zauważ, że
INC(przyrost) jest ujemny, aDEC(zmniejszenie) jest dodatni! Tam, gdzie używaL#lubL#+1jakoP-alboQ-OPs, dzieje się to, że aktualizuje wskaźniki: zwiększanie, zmniejszanie, zamiana itp. Asembler został ręcznie skompilowany do PQRS poprzez zastąpienie etykiet przesunięciami. Poniżej znajduje się zoptymalizowane rozwiązanie PQRS :Powyższy kod można zapisać w
challenge-optimized.pqrscelu uruchomienia przypadków testowych.Dla kompletności, oto źródło według specyfikacji:
I rozwiązanie:
Aby uruchomić powyższego, trzeba będzie wypowiedzieć się
#define OPTIMIZEDi dodać#define PER_SPECSwpqrs.ci rekompilacji.To było wielkie wyzwanie - naprawdę podobał mi się trening mentalny! Wróciłem do moich dawnych dni asemblera 6502 ...
Gdybym zaimplementował PQRS jako „prawdziwy” język programowania, prawdopodobnie dodałbym dodatkowe tryby bezpośredniego i podwójnie pośredniego dostępu oprócz dostępu pośredniego, a także pozycję względną i pozycję bezwzględną, obie z opcjami pośredniego dostępu do rozgałęzienia!
źródło
Cynk, pęknięty! autor: @Zgarb
Dostępne również w GitHub .
Potrzebujesz Dart 1.12 i Pub. Wystarczy uruchomić,
pub getaby pobrać jedyną zależność, bibliotekę analizującą.Mam nadzieję, że ten trwa dłużej niż 30 minut! : O
Język
Cynk jest zorientowany na redefiniowanie operatorów. Możesz łatwo przedefiniować wszystkie operatory w języku!
Struktura typowego programu Cynk wygląda następująco:
Istnieją tylko dwa typy danych: liczby całkowite i zestawy. Nie ma czegoś takiego jak literał zestawu, a puste zestawy są niedozwolone.
Wyrażenia
Poniżej przedstawiono prawidłowe wyrażenia w cynku:
Literały
Cynk obsługuje wszystkie normalne literały całkowite, takie jak
1i-2.Zmienne
Cynk ma zmienne (jak większość języków). Aby się do nich odwołać, wystarczy użyć nazwy. Znowu jak większość języków!
Istnieje jednak specjalna zmienna o nazwie,
Sktóra zachowuje się trochę jak PythQ. Kiedy po raz pierwszy go użyjesz, odczyta wiersz ze standardowego wejścia i zinterpretuje go jako zestaw liczb. Na przykład linia wprowadzania1234231zmieniłaby się w zestaw{1, 2, 3, 4, 3, 2, 1}.WAŻNA UWAGA!!! W niektórych przypadkach literał na końcu zastąpienia operatora jest niepoprawnie analizowany, więc musisz go otoczyć nawiasami.
Operacje binarne
Obsługiwane są następujące operacje binarne:
+:1+1.-:1-1.*:2*2./:4/2.=:3=3.Ponadto obsługiwane są również następujące operacje jednoargumentowe:
#:#x.Pierwszeństwo jest zawsze słuszne. Aby to zmienić, możesz użyć nawiasów okrągłych.
Tylko równość i długość działają na zestawach. Gdy spróbujesz uzyskać długość liczby całkowitej, otrzymasz liczbę cyfr w jej reprezentacji ciągu.
Ustaw zrozumienie
Aby manipulować zestawami, cynk ma zrozumienie. Wyglądają tak:
Klauzula jest klauzulą when i sort.
Gdy klauzula wygląda
^<expression>. Wyrażenie następujące po znaku karetki musi skutkować liczbą całkowitą. Użycie klauzuli when zajmie tylko elementy zestawu, dla którychexpressionnie jest zero. W wyrażeniu zmienna_zostanie ustawiona na bieżący indeks w zestawie. Jest to mniej więcej odpowiednik tego Pythona:Klauzula porządek , który wygląda
$<expression>, sortuje zestaw malejąco według wartości<expression>. Jest równy temu Pythonowi:Oto kilka przykładów zrozumienia:
Weź tylko te elementy zestawu,
sktóre są równe 5:Posortuj zestaw
swedług wartości, jeśli jego elementy zostaną podniesione do kwadratu:Zastępuje
Przesłonięcia operatorów pozwalają przedefiniować operatorów. Wyglądają tak:
lub:
W pierwszym przypadku możesz zdefiniować operatora, aby był równy innemu operatorowi. Na przykład mogę zdefiniować
+odejmowanie za pomocą:Gdy to zrobisz, możesz ponownie zdefiniować operatora, aby był magicznym operatorem . Istnieją dwa magiczne operatory:
joinpobiera zestaw i liczbę całkowitą i dołącza do zawartości zestawu. Na przykład dołączenie{1, 2, 3}do4spowoduje liczbę całkowitą14243.cutbierze również zestaw i liczbę całkowitą i dzieli zestaw przy każdym wystąpieniu liczby całkowitej. Używaniecutna{1, 3, 9, 4, 3, 2}i3stworzy{{1}, {9, 4}, {2}}... ALE wszystkie zestawy jednoelementowe są spłaszczone, więc tak naprawdę będzie{1, {9, 4}, 2}.Oto przykład, który redefiniuje
+operatora w ten sposóbjoin:W tym drugim przypadku możesz ponownie zdefiniować operator dla podanego wyrażenia. Jako przykład definiuje to operację plus, aby dodać wartości, a następnie dodać 1:
Ale co to jest
+:? Możesz dołączyć dwukropek:do operatora, aby zawsze używać wbudowanej wersji. W tym przykładzie użyto wbudowanego+przez,+:aby dodać liczby razem, a następnie dodaje 1 (pamiętaj, że wszystko jest poprawnie skojarzone).Przesłanianie operatora długości wygląda tak:
Zauważ, że prawie wszystkie wbudowane operacje (oprócz równości) użyją tego operatora długości do określenia długości zestawu. Jeśli zdefiniowałeś to jako:
każda część cynku, która działa na zestawach, z wyjątkiem
=działałaby tylko na pierwszym elemencie zestawu, który został podany.Wiele przesłonięć
Możesz zastąpić wielu operatorów, oddzielając je przecinkami:
Druk
Nie możesz bezpośrednio wydrukować niczego w Cynku. Wynik następującego wyrażenia
inzostanie wydrukowany. Wartości zestawu zostaną połączone z separatorem. Weźmy na przykład:Jeśli
exprjest ustawiony{1, 3, {2, 4}},1324zostanie wydrukowany na ekranie po zakończeniu programu.Kładąc wszystko razem
Oto prosty program cynku, który wydaje się dodawać,
2+2ale powoduje, że wynik wynosi 5:Tłumacz
To idzie w
bin/zinc.dart:I to idzie w
pubspec.yaml:Zamierzone rozwiązanie
źródło
joinmieszany zestaw{1,{3,2}}, czy wystąpi błąd? Nie mogę teraz zainstalować Dart, więc nie mogę się sprawdzić.dart bin/zinc.dart test.znc, pojawi się błąd składniowy:'file:///D:/Development/languages/zinc/bin/zinc.dart': error: line 323 pos 41: unexpected token '?'...var input = stdin.readLineSync() ?? '';-2+#:Sgdy podanoS, co odciąło dwa zera końcowe. Tak miałem nadzieję, że zostanie to rozwiązane. I^nie ma odwracać zestawu ... to był błąd ...Zupa Kompasowa ( spękana kartonem )
Tłumacz: C ++
Zupa kompasowa przypomina maszynę Turinga z nieskończoną 2-wymiarową taśmą. Głównym problemem jest to, że pamięć instrukcji i pamięć danych znajdują się w tej samej przestrzeni, a wyjściem programu jest cała zawartość tej przestrzeni.
Jak to działa
Program jest dwuwymiarowym blokiem tekstu. Przestrzeń programu zaczyna się od całego kodu źródłowego umieszczonego z pierwszym znakiem na (0,0). Reszta przestrzeni programu jest nieskończona i jest inicjowana znakami zerowymi (ASCII 0).
Istnieją dwa wskaźniki, które mogą poruszać się po przestrzeni programu:
!postaci lub w (0,0), jeśli to nie istnieje.x,X,y, iY. Zaczyna się w miejscu@postaci lub w (0,0), jeśli to nie istnieje.Wejście
Zawartość stdin jest drukowana w przestrzeni programu, zaczynając od lokalizacji
>znaku lub w (0,0), jeśli to nie istnieje.Wynik
Program kończy się, gdy wskaźnik wykonania bezpowrotnie wykracza poza granice. Dane wyjściowe to cała zawartość przestrzeni programu w tym czasie. Jest wysyłany do stdout i „result.txt”.
Instrukcje
n- przekierowuje wskaźnik wykonania Północ (ujemne y)e- przekierowuje wskaźnik wykonania Wschód (dodatni x)s- przekierowuje wskaźnik wykonania South (dodatnie y)w- przekierowuje wskaźnik wykonania West (ujemny x)y- przesuwa wskaźnik danych na północ (y ujemne)X- przesuwa wskaźnik danych na wschód (dodatni x)Y- przesuwa wskaźnik danych na południe (dodatnie y)x- przesuwa wskaźnik danych na zachód (ujemny x)p- zapisuje następny znak napotkany przez wskaźnik wykonania na wskaźniku danych. Ta postać nie jest wykonywana jako instrukcja.j- sprawdza następny znak napotkany przez wskaźnik wykonania względem znaku pod wskaźnikiem danych. Ta postać nie jest wykonywana jako instrukcja. Jeśli są takie same, wskaźnik wykonania przeskakuje nad kolejnym znakiem.c- zapisuje znak zerowy we wskaźniku danych.*- punkt przerwania - powoduje tylko przerwanie tłumacza.Wszystkie pozostałe znaki są ignorowane przez wskaźnik wykonania.
Interpretator
Tłumacz interpretuje plik źródłowy jako argument i dane wejściowe na stdin. Ma krokowy debugger, który można wywołać za pomocą instrukcji punktu przerwania w code (
*). Po rozbiciu wskaźnik wykonania jest wyświetlany jako ASCII 178 (ciemniejszy blok zacieniowany), a wskaźnik danych jest wyświetlany jako ASCII 177 (jaśniejszy blok zacieniowany).Przykłady
Witaj świecie
Kot
Parzystość: akceptuje ciąg znaków zakończony zerem („0”). Wyprowadza
yesw pierwszym wierszu wyjścia, jeśli liczba 1s na wejściu jest nieparzysta, w przeciwnym razie wyprowadza|.Napiwki
Powinieneś użyć dobrego edytora tekstu i rozsądnie wykorzystać funkcjonalność klawisza „Wstaw”, a także użyć „Alt-Drag”, aby dodać lub usunąć tekst w wielu wierszach jednocześnie.
Rozwiązanie
Oto moje rozwiązanie. To nie jest tak ładne jak karton_box, ponieważ musiałem sam usunąć kod źródłowy. Miałem również nadzieję, że znajdę sposób na usunięcie całego kodu i pozostawienie tylko odpowiedzi, ale nie mogłem.
Moje podejście polegało na podzieleniu różnych sekwencji
1s na różne linie, a następnie posortowaniu ich, tak1aby wszystkie „s” opadały, aż uderzą w inną1, i na koniec wymazały wszystko oprócz trzeciej linii po wejściu.#A#odczytuje1s i kopiuje je do ostatniej linii podziału aż do a0zostanie odczytany a.#B#sprawdza sekundę0i jedzie na północ,#D#tam jest jedna. W przeciwnym razie#C#rozpoczyna nową linię podziału, umieszczając|za ostatnią i wraca do#A#.#F#to kod grawitacji.1Przechodzi do ostatniego z pierwszego rzędu i przesuwa go w górę, aż uderzy1lub-. Jeśli nie może tego zrobić, oznacza wiersz jako zakończony, umieszczając+przed nim.#G#usuwa wszystkie niepotrzebne podziały i#H#usuwa standardowe wejście oraz cały kod między nawiasami.Kod:
źródło
cna początku było coś, czego nie powinno być. Naprawiłem to. Dodałem również moje rozwiązanie problemu.Acc! , Cracc'd autor: ppperry
Ten język ma jedną strukturę zapętlającą, podstawową matematykę całkowitą, we / wy znaków i akumulator (stąd nazwa). Tylko jeden akumulator. Tak więc nazwa.
Sprawozdania
Polecenia są analizowane linia po linii. Istnieją trzy rodzaje poleceń:
Count <var> while <cond>Liczy się
<var>w górę od 0 ile<cond>nie jest zerem, co odpowiada stylu Cfor(<var>=0; <cond>; <var>++). Licznikiem pętli może być dowolna pojedyncza mała litera. Warunkiem może być dowolne wyrażenie, niekoniecznie obejmujące zmienną pętli. Pętla zatrzymuje się, gdy wartość warunku staje się 0.Pętle wymagają nawiasów klamrowych w stylu K&R (w szczególności wariant Stroustrup ):
Write <charcode>Wysyła pojedynczy znak o podanej wartości ASCII / Unicode na standardowe wyjście. Kod znaków może być dowolnym wyrażeniem.
Każde wyrażenie stojące samo w sobie jest oceniane i przypisywane z powrotem do akumulatora (który jest dostępny jako
_). Zatem np.3Jest stwierdzeniem, które ustawia akumulator na 3;_ + 1zwiększa akumulator; i_ * Nodczytuje znak i mnoży akumulator przez jego kod znaków.Uwaga: akumulator jest jedyną zmienną, do której można bezpośrednio przypisać; zmienne pętlowe i
Nmogą być używane w obliczeniach, ale nie mogą być modyfikowane.Akumulator ma początkowo wartość 0.
Wyrażenia
Wyrażenie może zawierać literały całkowite, zmienne pętli (
a-z)_dla akumulatora oraz specjalną wartośćN, która odczytuje znak i analizuje jego kod znaków za każdym razem, gdy jest używany. Uwaga: oznacza to, że masz tylko jeden strzał, aby przeczytać każdą postać; przy następnym użyciuNbędziesz czytać następny.Operatorzy to:
+, dodatek-, odejmowanie; jednoznaczna negacja*, mnożenie/, dzielenie liczb całkowitych%, modulo^, potęgowanieNawiasów można użyć w celu wymuszenia pierwszeństwa operacji. Każdy inny znak w wyrażeniu jest błędem składni.
Białe znaki i komentarze
Wiodące i końcowe białe znaki i puste linie są ignorowane. Biała spacja w nagłówkach pętli musi być dokładnie taka, jak pokazano, z pojedynczą spacją między nagłówkiem pętli i otwierającym nawias klamrowy. Białe spacje w wyrażeniach są opcjonalne.
#rozpoczyna komentarz jednowierszowy.Wejście wyjście
Acc! oczekuje jednego wiersza znaków jako danych wejściowych. Każdy znak wejściowy można pobrać kolejno, a jego kod znaków przetworzyć za pomocą
N. Próba odczytania ostatniego znaku linii powoduje błąd. Znak może zostać wyprowadzony poprzez przekazanie jego kodu znaków doWriteinstrukcji.Interpretator
Tłumacz (napisany w Pythonie 3) tłumaczy Acc! kod do Pythona i tak
execjest.źródło
GoToTape (bezpieczny)
(Wcześniej znany jako Simp-plex.)
Ten język jest prosty. Główną kontrolą przepływu jest goto, najbardziej naturalna i użyteczna forma kontroli.
Specyfikacja języka
Dane są przechowywane na taśmie i akumulatorze. Działa całkowicie z niepodpisanymi integracjami. Każda postać ma polecenie. Oto wszystkie polecenia:
a-zsą goto, idą doA-Zodpowiednio.:: ustaw akumulator na wartość ASCII na char z wejścia.~: wypisuje char dla wartości ASCII w akumulatorze.&: odejmij jeden z akumulatora, jeśli jest to 1 lub więcej, w przeciwnym razie dodaj jeden.|: dodaj jeden do akumulatora.<: ustaw wskaźnik danych na 0.+: zwiększyć komórkę danych na wskaźniku danych; przesuń wskaźnik o +1.-: odejmij jeden z komórki danych przy wskaźniku danych, jeśli jest dodatni; przesuń wskaźnik o +1.[...]: uruchom kod n razy, gdzie n jest liczbą na taśmie przy wskaźniku danych (nie można go zagnieździć)./: pomiń następną instrukcję, jeśli akumulator ma wartość 0.Tłumacz ustny (C ++)
Baw się dobrze!
Rozwiązanie
A:+&&&&&&&&&&/gbG&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&/a<aB<[|]C[&]-[|]/c<[|]D[&]-[|]/d<[|]+E[&]|||||||||||||||||||||||||||||||||||||||||||||||||~X&/x-[|]/eźródło
calloczamiastnew char, napisałeś pętlę while w stylu C, użyłeś zarządzania pamięcią w stylu C, zmusiłeś nas do ponownej kompilacji pliku C ++ za każdym razem, gdy zmieniamy kod, i użyliśmy 20 ifs zamiastswitch? Nie narzekam, ale teraz krwawią mi oczy ...: Ostr.c_str()aby uzyskaćchar*.To był zły pomysł, ponieważ prawie wszystkie ezoteryczne języki wyglądają na nieczytelne (spójrz na Jelly).
Ale oto idzie:
Pylongolf2 beta6
Pushing to the Stack
Pushing na stos działa inaczej niż w innych językach.
Kod
78pcha7i8na stosie, jednak w Pylongolf popycha78.W Pylongolf2 można to przełączać
Ü.Polecenia
Łączenie łańcuchów i usuwanie wzorca regex z łańcucha
Symbol + łączy łańcuchy.
Możesz użyć symbolu -, aby usunąć znaki następujące po wyrażeniu regularnym z łańcucha:
Ten kod pobiera dane wejściowe i usuwa wszystkie znaki niealfabetyczne, usuwając wszystkie pasujące wzorce
[^a-zA-Z].Wybrany element musi być wyrażeniem regularnym, a poprzedni musi być ciągiem do edycji.
Jeśli oświadczenia
Aby wykonać instrukcje if, umieść a,
=aby porównać wybrany element i następny.To umieszcza albo a
truealbo afalsena swoim miejscu.Polecenie
?sprawdza wartość logiczną.Jeśli tak,
trueto nic nie robi, a tłumacz kontynuuje.Jeśli tak,
falsetłumacz przeskakuje do najbliższego¿znaku.Zaczerpnięte ze strony Github.
Tłumacz dla Pylongolf2 (Java):
źródło
Rainbow (Uwaga: tłumacz wkrótce)
Wiem, że to wyzwanie wygasło.
Rainbow to mieszanka ... wielu rzeczy.
Rainbow to język oparty na stosach 2D z dwoma stosami (jak Brain-Flak) i 8 kierunkami (
N NE E SE S SW W NW). Istnieje 8 poleceń:1,+,*,"Robią dokładnie to, co robią w 1+.!przełącza aktywny stos.>obróć IP zgodnie z ruchem wskazówek zegara.,wprowadź znak i pchnij go..pop i wypisz znak.Jednak znaki w kodzie źródłowym nie są natychmiast wykonywane. Zamiast tego
[The Character in the source code]^[Top Of Stack]jest podawany do elementu Collatz Conjecture, a liczba kroków potrzebnych do osiągnięcia 1 jest konwertowana na postać według tabeli ASCII. Ta postać jest następnie wykonywana.Na początku programu kod źródłowy (z wyjątkiem ostatniego znaku) jest wypychany na stos.
Kiedy adres IP osiąga krawędź kodu źródłowego, zostaje zakończony.
Apokalipsa
n i m są dwoma rejestrami. Po wykonaniu
>instrukcji m jest zwiększane. Apokalipsa jest wyzwalana tylko wtedy, gdy m przekracza n. Kiedy dzieje się Apokalipsa, to:m jest początkowo zerowy, a n jest początkowo ostatnim znakiem kodu źródłowego.
Szyfrowanie
Po wykonaniu dowolnego kodu źródłowego jest szyfrowany. ASCII 1. znaku jest zwiększany o jeden, drugi jest zmniejszany o jeden, trzeci jest zwiększany o dwa, czwarty jest zmniejszany o dwa itd.
źródło