Rozumiem wydajność Ruby i Pythona. Co robi wydajność Scali?
312
Rozumiem wydajność Ruby i Pythona. Co robi wydajność Scali?
Jest używany w interpretacjach sekwencyjnych (takich jak listy-generatory Pythona i generatory, z których możesz także korzystać yield).
Jest stosowany w połączeniu z fori zapisuje nowy element w wynikowej sekwencji.
Prosty przykład (ze scala-lang )
/** Turn command line arguments to uppercase */
object Main {
def main(args: Array[String]) {
val res = for (a <- args) yield a.toUpperCase
println("Arguments: " + res.toString)
}
}Odpowiednie wyrażenie w F # byłoby
[ for a in args -> a.toUpperCase ]lub
from a in args select a.toUpperCase w Linq.
Ruby yieldma inny efekt.
Uważam, że zaakceptowana odpowiedź jest świetna, ale wydaje się, że wielu ludziom nie udało się zrozumieć pewnych podstawowych kwestii.
Po pierwsze,
forrozumienia Scali są równoważnedonotacji Haskella i nie są niczym więcej jak cukrem syntaktycznym do kompozycji wielu operacji monadycznych. Ponieważ to stwierdzenie najprawdopodobniej nie pomoże nikomu, kto potrzebuje pomocy, spróbujmy jeszcze raz… :-)Zrozumienia Scali
forto cukier składniowy do kompozycji wielu operacji z mapąflatMapifilter. Lubforeach. Scala faktycznie tłumaczyfor-wyrażenie na wywołania tych metod, więc każda klasa, która je udostępnia, lub ich podzbiór, może być używana ze zrozumieniem.Najpierw porozmawiajmy o tłumaczeniach. Istnieją bardzo proste zasady:
To
jest przetłumaczone na
To
jest przetłumaczone na
To
jest przetłumaczony na Scala 2.7 na
lub, na Scala 2.8, do
z rezerwą na poprzednie, jeśli metoda
withFilternie jest dostępna, alefilterjest. Więcej informacji na ten temat znajduje się w sekcji poniżej.To
jest przetłumaczone na
Kiedy patrzysz na bardzo proste
forpojęcia, alternatywymap/foreachwyglądają rzeczywiście lepiej. Gdy jednak zaczniesz je komponować, możesz łatwo zgubić się w poziomach nawiasów i zagnieżdżania. Kiedy tak się dzieje,forrozumienie jest zwykle znacznie wyraźniejsze.Pokażę jeden prosty przykład i celowo pominę wszelkie wyjaśnienia. Możesz zdecydować, która składnia była łatwiejsza do zrozumienia.
lub
withFilterScala 2.8 wprowadziła metodę o nazwie
withFilter, której główną różnicą jest to, że zamiast zwracać nową, przefiltrowaną kolekcję, filtruje na żądanie.filterMetoda ma swoje zachowanie zdefiniowane w oparciu o surowości kolekcji. Aby to lepiej zrozumieć, spójrzmy na Scala 2.7 zList(ścisłe) iStream(nie ścisłe):Różnica dzieje się, ponieważ
filterjest natychmiast stosowana zList, zwracając listę szans - ponieważfoundjestfalse. Dopiero wtedyforeachjest wykonywana, ale do tego czasu zmianafoundjest bez znaczenia, tak jakfilterjuż została wykonana.W przypadku
Streamwarunek nie jest natychmiast stosowany. Zamiast tego, zgodnie z żądaniem każdego elementuforeach,filtertestuje warunek, który pozwalaforeachna jego wpływfound. Żeby było jasne, oto kod równoważny dla zrozumienia:Powodowało to wiele problemów, ponieważ ludzie spodziewali się, że
ifbędą one uważane za dostępne na żądanie, zamiast wcześniejszego zastosowania do całej kolekcji.Wprowadzono Scala 2.8
withFilter, która zawsze nie jest ścisła, bez względu na surowość kolekcji. Poniższy przykład pokazujeListobie metody w Scali 2.8:Daje to wynik, którego większość ludzi oczekuje, bez zmiany
filterzachowania. Na marginesie,Rangezmieniono z nieprecyzyjnego na ścisłe między Scala 2.7 i Scala 2.8.źródło
withFilterma być również surowe, nawet w przypadku ścisłych kolekcji, które zasługują na wyjaśnienie. Rozważę to ...for(x <- c; y <- x; z <-y) {...}przetłumaczono nac.foreach(x => x.foreach(y => y.foreach(z => {...})))2.for(x <- c; y <- x; z <- y) yield {...}przetłumaczono nac.flatMap(x => x.flatMap(y => y.map(z => {...})))for(x <- c; y = ...) yield {...}naprawdę jest przetłumaczone nac.map(x => (x, ...)).map((x,y) => {...})? Myślę, że to jest przetłumaczone na,c.map(x => (x, ...)).map(x => { ...use x._1 and x._2 here...})czy coś mi brakuje?Tak, jak powiedział Earwicker, jest to prawie odpowiednik LINQ
selecti ma bardzo niewiele wspólnego z Ruby i Pythonemyield. Zasadniczo, gdzie w C # napiszeszw Scali masz zamiast tego
Ważne jest również, aby zrozumieć, że
for-zrozumienia nie działają tylko z sekwencjami, ale z każdym typem, który definiuje pewne metody, tak jak LINQ:map, pozwalafor-wyrażenia składające się z jednego generatora.flatMaprównieżmap, pozwala nafor-wyrażenia składające się z kilku generatorów.foreachpozwalafor-laops bez wydajności (zarówno z jednym, jak i wieloma generatorami).filterumożliwiaforwyrażenia -filter zaczynające sięifodforwyrażenia w.źródło
O ile nie uzyskasz lepszej odpowiedzi od użytkownika Scali (którego nie jestem), oto moje zrozumienie.
Pojawia się tylko jako część wyrażenia rozpoczynającego się od
for, które określa, jak wygenerować nową listę z istniejącej listy.Coś jak:
Jest więc jeden element wyjściowy dla każdego wejścia (chociaż uważam, że istnieje sposób na usunięcie duplikatów).
Jest to całkiem odmienne od „kontynuacji imperatywnych” włączonych przez funkcję fed w innych językach, gdzie zapewnia sposób generowania listy o dowolnej długości, z jakiegoś imperatywnego kodu o prawie dowolnej strukturze.
(Jeśli znasz C #, jest bliżej operatora LINQ
selectniż jestyield return).źródło
Słowem kluczowym
yieldw Scali jest po prostu cukier składniowy, który można łatwo zastąpić przezmap, jak szczegółowo wyjaśnił Daniel Sobral .Z drugiej strony
yieldjest całkowicie mylące, jeśli szukasz generatorów (lub kontynuacji) podobnych do tych w Pythonie . Zobacz ten wątek SO, aby uzyskać więcej informacji: Jaki jest preferowany sposób implementacji „fedrunku” w Scali?źródło
Rozważ następujące zrozumienie
Pomocne może być przeczytanie go na głos w następujący sposób
„ Dla każdej liczby całkowitej
i, jeśli jest ona większa niż3, wydaj (produkuj)ii dodaj ją do listyA”.Pod względem matematycznym notacji konstruktora zestawów powyższe rozumienie jest analogiczne do
który można odczytać jako
„ Dla każdej liczby całkowitej , jeśli jest ona większa niż
, jeśli jest ona większa niż 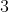 , to należy ona do zbioru
, to należy ona do zbioru 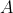 ”.
”.
lub alternatywnie jako
„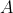 jest zbiorem wszystkich liczb całkowitych
jest zbiorem wszystkich liczb całkowitych  , z których każda
, z których każda  jest większa niż
jest większa niż 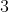 ”.
”.
źródło
Wydajność jest podobna do pętli for, która ma bufor, którego nie widzimy, i dla każdego przyrostu dodaje kolejny element do bufora. Gdy pętla for zakończy działanie, zwróci kolekcję wszystkich uzyskanych wartości. Wydajność może być używana jako proste operatory arytmetyczne lub nawet w połączeniu z tablicami. Oto dwa proste przykłady lepszego zrozumienia
res: scala.collection.immutable.IndexedSeq [Int] = Vector (3, 6, 9, 12, 15)
res: Seq [(Int, Char)] = List ((1, a), (1, b), (1, c), (2, a), (2, b), (2, c), ( 3, a), (3, b), (3, c))
Mam nadzieję że to pomoże!!
źródło
Te dwa fragmenty kodu są równoważne.
Te dwa fragmenty kodu są również równoważne.
Mapa jest tak elastyczna jak plon i odwrotnie.
źródło
wydajność jest bardziej elastyczna niż map (), patrz przykład poniżej
wydajność wydrukuje wynik taki jak: Lista (5, 6), co jest dobre
podczas gdy map () zwróci wynik: List (false, false, true, true, true), co prawdopodobnie nie jest tym, co zamierzasz.
źródło