Jak bym zabrał się do wygenerowania listy wszystkich możliwych permutacji łańcucha o długości od x do y, zawierającego zmienną listę znaków.
Każdy język działałby, ale powinien być przenośny.
string
language-agnostic
cross-platform
UnkwnTech
źródło
źródło
Odpowiedzi:
Można to zrobić na kilka sposobów. Typowe metody wykorzystują rekursję, zapamiętywanie lub programowanie dynamiczne. Podstawowa idea polega na tym, że tworzysz listę wszystkich ciągów o długości 1, a następnie w każdej iteracji, dla wszystkich napisów utworzonych w ostatniej iteracji, dodajesz ten ciąg połączony z każdym znakiem w ciągu osobno. (indeks zmiennej w poniższym kodzie śledzi początek ostatniej i następnej iteracji)
Jakiś pseudokod:
musiałbyś wtedy usunąć wszystkie ciągi o długości mniejszej niż x, będą to pierwsze (x-1) * len (originalString) wpisy na liście.
źródło
Lepiej jest używać cofania
źródło
Dostaniesz dużo strun, to na pewno ...
Gdzie x i y to sposób ich definiowania, a r to liczba znaków, z których wybieramy - jeśli dobrze cię rozumiem. Zdecydowanie powinieneś je generować w razie potrzeby i nie robić niechlujstwa i mówić, wygeneruj zestaw mocy, a następnie przefiltruj długość ciągów.
Poniższe zdecydowanie nie są najlepszym sposobem na ich wygenerowanie, ale mimo wszystko jest to interesujące.
Knuth (tom 4, zeszyt 2, 7.2.1.3) mówi nam, że (s, t) -kombinacja jest równoważna s + 1 rzeczy wziętej t naraz z powtórzeniem - kombinacja (s, t) -jest używana przez Knutha to jest równe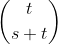 . Możemy to rozgryźć, najpierw generując każdą kombinację (s, t) w postaci binarnej (czyli o długości (s + t)) i zliczając liczbę 0 po lewej stronie każdego 1.
. Możemy to rozgryźć, najpierw generując każdą kombinację (s, t) w postaci binarnej (czyli o długości (s + t)) i zliczając liczbę 0 po lewej stronie każdego 1.
10001000011101 -> staje się permutacją: {0, 3, 4, 4, 4, 1}
źródło
Rozwiązanie nierekurencyjne według Knutha, przykład w Pythonie:
źródło
"54321"tylko z JEDNYM ciągiem, zostanie wyświetlony (sam).nextPermutation()to bezstanowe - do permutacji potrzebne są tylko dane wejściowe, a indeksy nie są obsługiwane od iteracji do iteracji. Jest w stanie to zrobić, zakładając, że początkowe dane wejściowe zostały posortowane i znajdując indeksy (k0il0) samodzielnie, na podstawie tego, gdzie zachowana jest kolejność. Sortowanie danych wejściowych, takich jak „54321” -> „12345”, umożliwiłoby temu algorytmowi znalezienie wszystkich oczekiwanych permutacji. Ale ponieważ wykonuje dużo dodatkowej pracy, aby ponownie znaleźć te indeksy dla każdej generowanej przez siebie permutacji, istnieją bardziej wydajne sposoby zrobienia tego nierekurencyjnie.Możesz spojrzeć na „ Efektywne wyliczanie podzbiorów zbioru ”, które opisuje algorytm, który wykonuje część tego, co chcesz - szybko generuje wszystkie podzbiory N znaków od długości x do y. Zawiera implementację w C.
Dla każdego podzbioru nadal musiałbyś wygenerować wszystkie permutacje. Na przykład, jeśli chcesz mieć 3 znaki z „abcde”, ten algorytm dałby ci „abc”, „abd”, „abe” ... ale musisz permutować każdy z nich, aby uzyskać „acb”, „bac”, „bca” itp.
źródło
Część działającego kodu Java w oparciu o odpowiedź Sarpa :
źródło
Oto proste rozwiązanie w C #.
Generuje tylko różne permutacje danego ciągu.
źródło
Jest tu wiele dobrych odpowiedzi. Proponuję również bardzo proste rozwiązanie rekurencyjne w C ++.
Uwaga : ciągi z powtarzającymi się znakami nie spowodują unikalnych permutacji.
źródło
Właśnie podniosłem to szybko w Rubim:
Możesz zajrzeć do API języka dla wbudowanych funkcji typu permutacji i być może będziesz w stanie napisać bardziej zoptymalizowany kod, ale jeśli liczby są aż tak wysokie, nie jestem pewien, czy istnieje wiele sposobów na obejście wielu wyników .
Tak czy inaczej, idea kodu zaczyna się od łańcucha o długości 0, a następnie śledzi wszystkie ciągi o długości Z, gdzie Z jest bieżącym rozmiarem w iteracji. Następnie przejdź przez każdy ciąg i dołącz każdy znak do każdego ciągu. Na koniec usuń wszystko, co było poniżej progu x, i zwróć wynik.
Nie testowałem tego z potencjalnie bezsensownymi danymi wejściowymi (lista znaków zerowych, dziwne wartości x i y itp.).
źródło
To jest tłumaczenie wersji Ruby Mike'a na Common Lisp:
I inna wersja, nieco krótsza i wykorzystująca więcej funkcji pętli:
źródło
Oto proste rozwiązanie rekurencyjne w języku C #:
Metoda:
Powołanie:
źródło
... a oto wersja C:
źródło
Drukuje wszystkie permutacje bez duplikatów
źródło
Rozwiązanie rekurencyjne w C ++
źródło
W Perlu, jeśli chcesz ograniczyć się do małych liter, możesz to zrobić:
Daje to wszystkie możliwe ciągi od 1 do 4 znaków z małymi literami. Zmień na wielkie litery
"a"na"A"i"zzzz"na"ZZZZ".W przypadku przypadków mieszanych staje się to znacznie trudniejsze i prawdopodobnie nie da się tego zrobić z jednym z wbudowanych operatorów Perla, takich jak ten.
źródło
Odpowiedź Ruby, która działa:
źródło
źródło
Następująca rekurencja Java wypisuje wszystkie permutacje danego ciągu:
Poniżej znajduje się zaktualizowana wersja powyższej metody "permut", która sprawia, że n! (n silnia) mniej rekurencyjnych wywołań w porównaniu z powyższą metodą
źródło
Nie jestem pewien, dlaczego chcesz to zrobić w pierwszej kolejności. Wynikowy zbiór dla dowolnych umiarkowanie dużych wartości x i y będzie ogromny i będzie rósł wykładniczo, gdy x i / lub y będą rosły.
Powiedzmy, że twój zestaw możliwych znaków to 26 małych liter alfabetu i poprosisz aplikację o wygenerowanie wszystkich permutacji, gdzie długość = 5. Zakładając, że nie zabraknie Ci pamięci, otrzymasz 11.881.376 (tj. 26 do potęgi 5) ciągi z powrotem. Zwiększ tę długość do 6, a otrzymasz 308 915 776 strun. Te liczby stają się boleśnie duże, bardzo szybko.
Oto rozwiązanie, które stworzyłem w Javie. Musisz podać dwa argumenty czasu wykonywania (odpowiadające x i y). Baw się dobrze.
źródło
Oto nierekurencyjna wersja, którą wymyśliłem, w javascript. Nie jest oparty na powyższym nierekurencyjnym Knutha, chociaż ma pewne podobieństwa w zamianie elementów. Sprawdziłem jego poprawność dla tablic wejściowych do 8 elementów.
Szybką optymalizacją byłoby przygotowanie
outtablicy do lotu i unikaniepush().Podstawowa idea to:
Mając jedną tablicę źródłową, wygeneruj pierwszy nowy zestaw tablic, które zamieniają pierwszy element z każdym kolejnym elementem po kolei, za każdym razem pozostawiając pozostałe elementy niezakłócone. np .: podane 1234, wygeneruj 1234, 2134, 3214, 4231.
Użyj każdej tablicy z poprzedniego przebiegu jako ziarna dla nowego przebiegu, ale zamiast zamieniać pierwszy element, zamień drugi element z każdym kolejnym elementem. Tym razem nie dołączaj oryginalnej tablicy do danych wyjściowych.
Powtarzaj krok 2, aż skończysz.
Oto przykładowy kod:
źródło
W rubinie:
Jest to dość szybkie, ale zajmie to trochę czasu =). Oczywiście możesz zacząć od „aaaaaaaa”, jeśli krótkie struny cię nie interesują.
Mogłem jednak źle zinterpretować rzeczywiste pytanie - w jednym z postów brzmiało to tak, jakbyś potrzebował brutalnej biblioteki strun, ale w głównym pytaniu brzmi to tak, jakbyś musiał permutować konkretny ciąg.
Twój problem jest nieco podobny do tego: http://beust.com/weblog/archives/000491.html ( wypisz wszystkie liczby całkowite, w których żadna z cyfr się nie powtarza, co spowodowało, że wiele języków go rozwiązało, z ocaml, który używa permutacji, i jakiś java, używając jeszcze innego rozwiązania).
źródło
Potrzebowałem tego dzisiaj i chociaż odpowiedzi już udzielone wskazały mi właściwy kierunek, nie były one tym, czego chciałem.
Oto implementacja wykorzystująca metodę Heapa. Długość tablicy musi wynosić co najmniej 3, a ze względów praktycznych nie więcej niż 10, w zależności od tego, co chcesz zrobić, cierpliwości i szybkości zegara.
Przed wprowadzeniem pętli, zainicjować
Perm(1 To N)z pierwszym permutacji,Stack(3 To N)z zer * orazLevelz2**. Na końcu wywołania pętliNextPerm, które zwróci false, gdy skończymy.* VB zrobi to za Ciebie.
** Możesz trochę zmienić NextPerm, aby było to niepotrzebne, ale jest to wyraźniejsze w ten sposób.
Inne metody są opisane przez różnych autorów. Knuth opisuje dwa, jeden daje porządek leksykalny, ale jest złożony i powolny, drugi jest znany jako metoda prostych zmian. Jie Gao i Dianjun Wang również napisali interesujący artykuł.
źródło
Ten kod w Pythonie, wywołany z
allowed_charactersustawieniem na[0,1]i maksymalnie 4 znakami, wygeneruje 2 ^ 4 wyników:['0000', '0001', '0010', '0011', '0100', '0101', '0110', '0111', '1000', '1001', '1010', '1011', '1100', '1101', '1110', '1111']Mam nadzieję, że to ci się przyda. Działa z każdym znakiem, nie tylko cyframi
źródło
Oto łącze, które opisuje, jak wydrukować permutacje ciągu. http://nipun-linuxtips.blogspot.in/2012/11/print-all-permutations-of-characters-in.html
źródło
Chociaż to nie odpowiada dokładnie na twoje pytanie, oto jeden sposób na wygenerowanie każdej permutacji liter z wielu ciągów o tej samej długości: np. Jeśli twoje słowa to „kawa”, „joomla” i „moodle”, możesz oczekuj wyników, takich jak „coodle”, „joodee”, „joffle” itp.
Zasadniczo liczba kombinacji to (liczba słów) do potęgi (liczba liter na słowo). Wybierz więc losową liczbę z przedziału od 0 do liczby kombinacji - 1, zamień tę liczbę na podstawę (liczbę słów), a następnie użyj każdej cyfry tej liczby jako wskaźnika, z którego słowa należy wziąć następną literę.
np. w powyższym przykładzie. 3 słowa, 6 liter = 729 kombinacji. Wybierz losową liczbę: 465. Konwertuj na podstawę 3: 122020. Weź pierwszą literę ze słowa 1, drugą ze słowa 2, trzecią ze słowa 2, czwartą ze słowa 0 ... a otrzymasz ... „joofle”.
Jeśli chcesz uzyskać wszystkie permutacje, po prostu zapętlaj od 0 do 728. Oczywiście, jeśli wybierasz tylko jedną losową wartość, znacznie
prostszym,mniej zagmatwanym sposobem byłoby zapętlenie nad literami. Ta metoda pozwala uniknąć rekurencji, jeśli chcesz mieć wszystkie permutacje, a także sprawia, że wyglądasz tak, jakbyś znał matematykę (tm) !Jeśli liczba kombinacji jest nadmierna, możesz podzielić ją na serię mniejszych słów i połączyć je na końcu.
źródło
c # iteracyjny:
źródło
źródło
Oto moje podejście do wersji nierekurencyjnej
źródło
Rozwiązanie pytoniczne:
źródło
Oto eleganckie, nierekurencyjne rozwiązanie O (n!):
źródło